
For 20 years, I sat inside some of the world’s most influential companies, helping populate dashboards with data. Executives would nod, and strategies would follow. I knew where the data came from and how it was collected, and I realized it didn’t reflect people. It reflected the shadows people cast as they moved through systems never designed with them in mind.
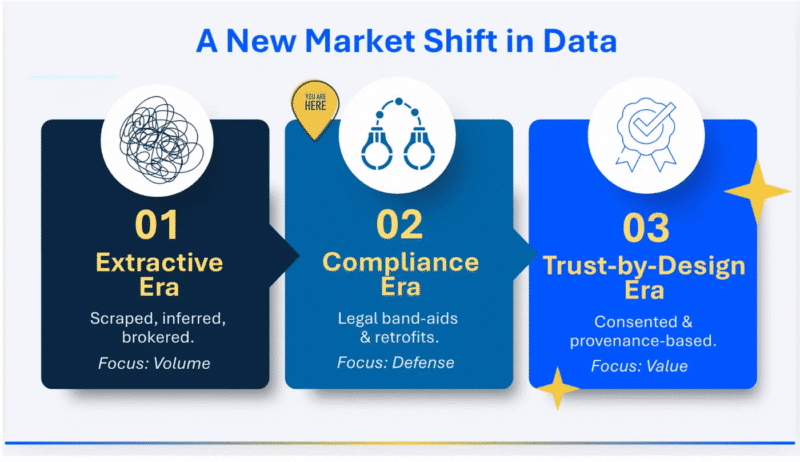
We were making decisions based on signals scraped, inferred, packaged, and resold so many times that the human being at the origin was barely a ghost by the time the insight reached us.
I spent years trying to make peace with it. I told myself the friction was technical, a legacy infrastructure problem, a data quality problem, a pipeline problem. If we just built better data cleanrooms, better customer data platforms, and more sophisticated brokers, we could get to the truth beneath the surface. I believed that the disorder was an engineering challenge waiting for the right solution.
The plumbing wasn’t the issue. The architecture was. We built an entire economy on a foundational premise that treated people as raw material rather than participants. The incentive wasn’t to understand the person. It was to extract. The extraction of signal over human understanding became our standard, leaving every subsequent clean fix compromised by that foundational error.
This model succeeded because its consequences remained hidden.
- Personal information was harvested without the individual’s awareness.
- This data was traded to unknown entities and merged with obscure records.
- The resulting inferences were used to categorize and judge them.
This lack of immediate impact is deceptive. The true violence of surveillance capitalism is structural, embedded within the system’s architecture rather than isolated choices. That structure makes it nearly invisible to those within it and incredibly difficult to undo once recognized.
The silent rot of dirty data
The crisis operates much like a silent medical condition, such as high cholesterol or prediabetes. You don’t feel the damage accumulating. You assume everything is fine, right up until it isn’t.
By the time dirty data manifests in your life, the collapse feels sudden. The rot was always there, quietly compounding. When it finally surfaces, it looks like this:
- Your wallet: Surveillance pricing algorithms use flawed behavioral data to automatically spike the cost of essential goods during moments of vulnerability. They don’t offer a fair deal — they rig the game before you can think.
- Your career: More than 90% of mid-to-large employers outsource hiring decisions to automated screening tools, creating algorithmic monocultures in which qualified candidates face systematic rejection across entire industries without a single human reviewing their applications.
- Your health: Malicious ad networks deploy thousands of deepfake video campaigns to manipulate vulnerable consumers into purchasing unverified products, with platforms unchecked that prioritize ad revenue over human safety.
- Your family: Data-targeted financial products turn everyday decisions into aggressive extraction engines, with frictionless digital design driving measurable spikes in household bankruptcy and consumer debt delinquency.
These aren’t edge cases. They’re the predictable output of a system built on dirty data operating at industrial scale.
The SEO toolkit you know, plus the AI visibility data you need.

Influence versus algorithmic manipulation
Legal scholar Dr. Cass Sunstein draws a useful distinction between legitimate influence and algorithmic manipulation. Healthy market influence appeals to your capacity for conscious, logical reflection — a transparent discount modifies your environment but allows you to make an informed choice.
Manipulation is different. A system becomes manipulative when it intentionally bypasses your capacity for rational decision-making, targeting subconscious vulnerabilities rather than engaging your judgment.
Most of what passes for personalization today falls on the wrong side of that line. It isn’t serving you. It’s working around you.
Measuring the liability
I didn’t change my mind because of an ethical awakening. It was watching those invisible costs become visible. A breach here. A regulatory penalty there. A news cycle about a data broker most people had never heard of, which held files on millions of people who had never consented to being profiled.
Slowly, then all at once, the bill for two decades of carelessness started arriving. The numbers were staggering. They exposed the fragility of the entire system. The data economy that was supposed to democratize access to intelligence created a liability so diffuse and so deeply embedded that most organizations can’t even map it, let alone defend against it.
Trust, consent, and data quality can reinforce one another. In this model, the person behind the data isn’t an afterthought. They participate in the relationship. The information organizations rely on is accurate because the source can verify it. The chain of custody is clear. Consent is specific. Control is meaningful.
Compounding the risk with enterprise AI
Information grounded in transparency and participation is more accurate, more durable, and more defensible than information assembled through layers of inference, aggregation, and resale.
The companies that make this shift will have better compliance posture, lower breach liability, and something others can’t easily replicate: a record of trust. A history of asking what they owed the people behind the data.
That question changes everything about how you build — and it’s long overdue.
The post Why trust belongs at the center of your data strategy appeared first on MarTech.