
Marketers embraced AI when it was priced like an all-you-can-eat buffet. Providers’ shift to token-based pricing comes just as agentic workflows are becoming part of everyday marketing — and agents use many, many tokens. Martech’s infrastructure needs to change if it’s going to keep costs down amid growing demand.
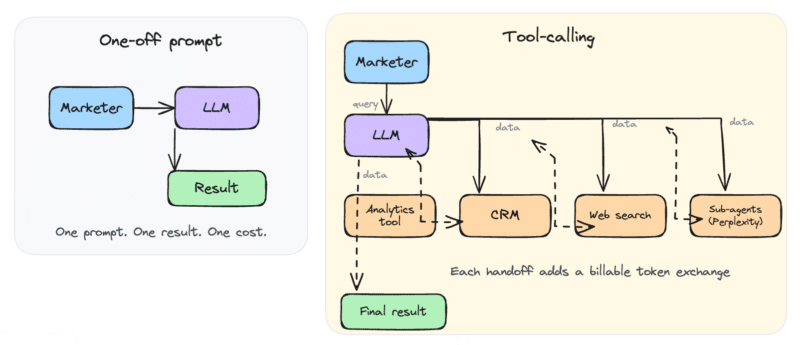
The moment AI connects to your business systems, the chatbot becomes much more powerful. Instead of answering one question at a time, it can pull customer records from your CRM, analyze campaign performance, search the web, and generate a personalized report in a single workflow. That’s made possible by tool calling, which lets AI access external systems via APIs and Model Context Protocol (MCP) connections.
The result is a huge productivity boost for marketers. AI can chain together multiple tools without requiring users to jump between applications. The catch is that every tool call consumes tokens. AI agents, in particular, use an incredible number of them because they pass the entire task history, their internal reasoning, and any external tool data back through the model at every step of their problem-solving loop.
The token cap reality
Let’s look at a real-world example of how that works.
A typical daily pipeline — search 200 results, summarize them, generate five headline variations — can easily run 4,000 to 5,000 tokens or more per run. Over a 30-day month, that can reach well over 100,000 tokens, well past the free-tier limits on OpenAI, Anthropic, and similar platforms, and even enough to blow through a $20 subscription well before the month is over.
(All token estimates in this article are based on standard tokenization metrics used across the industry — the same method providers use to calculate your bill. They are rough projections, not exact measurements from a live pipeline, and actual usage will vary based on model, prompt structure, and output length.)
Why Claude Cowork and similar workflows hit the wall
Unfortunately, there’s no correlation between the amount of tokens used and the quality of the result. As Scott Brinker and Frans Riemersma note in the State of Martech 2026 report, “more input does not automatically mean better output” — but you are still paying for every bit of it.
Claude Cowork and other tool-heavy environments make the problem visible fast. Every file read, every search, every API call adds a billable token interaction. Users who start the month with a $20 subscription often find themselves throttled by week two.
The consequence is choosing between throttling your workflow or paying astounding overage fees. Neither is sustainable for a marketing team that needs to run pipelines daily.
The answer is owned context, not a single provider
Fortunately, there is a solution: Keep the raw data under your control. Store it in a shared team database like PostgreSQL or Qdrant, in a cloud data warehouse like Snowflake or BigQuery, or in a folder in shared cloud storage — and use lightweight, non-LLM filtering logic to pull out relevant pieces before anything touches the model.
Setting that up might involve an LLM once, the same way you might use an AI assistant to write a formula or a script. But once it is in place, it runs automatically on every batch of new data — and it does not call an LLM at all. Simple keyword scoring or vector similarity search, both orders of magnitude cheaper than an LLM call, rank the data by relevance.
When a social listening pipeline pulls 500 tweets about a brand, the filtering step quietly selects the 10 most relevant ones and sends only those to the model. The token bill typically drops by 60% or more. The insight quality stays the same.
Beyond the one-off agent
There are a number of tools that can do this type of filtering. The open-source Hermes Agent, Claude Cowork, Claude Code, and Perplexity Computer all connect an LLM to external tools, allowing it to call APIs, read files, and automate workflows that can require switching between half a dozen applications. However, Hermes runs on your infrastructure and is provider-agnostic. The others are tied to the models and infrastructure of Anthropic and Perplexity.
Other notable tools in the broader agent ecosystem include:
- OpenClaw (380K+ GitHub stars), an open-source agent harness that pairs with filesystem-based memory stores;
- OpenAI Codex CLI (93K stars), which gives developers terminal-based agent access with local file persistence; and
- Orchestration frameworks like LangChain (140K stars) and CrewAI (54K stars), which you build against rather than use directly.
What they all share, in different ways, is that the model is a guest in your system, not the landlord.
Hermes takes that principle to a good extreme. It maintains a persistent local context store — your conversation history, tool outputs, and embeddings are in your database and accessible across sessions. A memory layer on top of that learns from each interaction, capturing preferences, corrections, and recurring patterns so the agent improves over time rather than starting fresh each session.
The SEO toolkit you know, plus the AI visibility data you need.

Its built-in tool ecosystem (web, terminal, APIs, vision, Python) means the same pipeline that pulls Salesforce or HubSpot records, checks a data warehouse, and drafts a report, also captures the intermediate results and saves them locally. And, because it is provider-agnostic, you only need to change a config line to go from OpenRouter to a self-hosted LLaMA.
The product is the implementation. The pattern is what matters — and any team can adopt it. The message is not “use Hermes Agent.” The message is “start building the systems that let you own your context, because the provider-centric approach cannot scale.”
The momentum behind agentic, context-owning tools is unmistakable. But the real question these tools force is strategic: do you want to pay for the work, or own the infrastructure and pay for the reasoning? Switch to a bigger subscription, and you’re still likely to run out of capacity. A different architecture removes that issue entirely. The choice every marketing team faces is which side of that equation they want to be on.
This is the first in a three-part series on the shift toward agentic marketing workflows and the infrastructure required to support them. In Part 2, I walk through how the architecture works in practice. Part 3 covers getting started with Hermes Desktop — the actual installation, skills, and workflows.
The post Agentic AI is rewriting martech economics and infrastructure appeared first on MarTech.